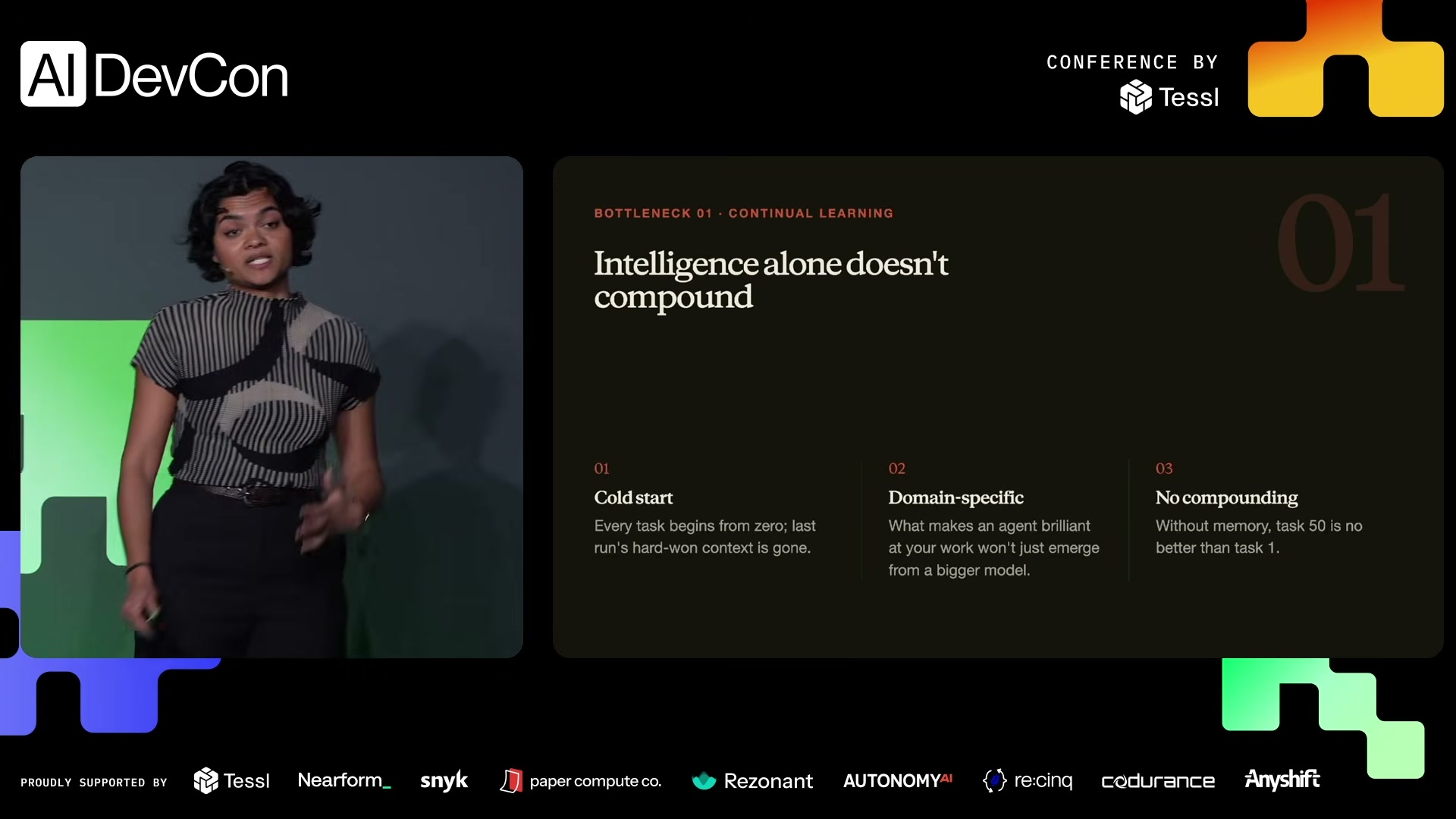
演讲幻灯片:Intelligence alone doesn't compound — 冷启动、领域特定、无累积效应
一、核心问题:模型越来越聪明,但 Agent 不会
这场演讲的起点,是一个在 AI Agent 部署中反复出现的问题:模型越来越聪明,但你的 Agent 并没有因此变得更好。Lamis Mukta 在 Anthropic 的日常工作是跟创业者一起把 Claude 推到能力极限,她见到的最大瓶颈不是模型本身,而是上下文。
"Models are more and more intelligent. But when it comes to actually deploying these models in your agents, the intelligence alone is not going to compound because they need this context that helps them perform the specific tasks."
第 50 次执行任务和第 1 次没有区别——Agent 不了解你的代码库、不记得你的偏好、不会从错误中学习。这就是Context Engineering要解决的问题:把模型的"裸智能"转化成在特定组织和任务中持久有效的能力。
"It's a really great investment to work on the context engineering part because this over time has the effect of multiplying the intelligence even as models get smarter."
二、一年走过四代:从 Markdown 到自主记忆
Lamis 回顾了 Anthropic 在过去一年中 Context Engineering 的四步进化。核心原则只有一条:Do the simple thing that works。

演讲幻灯片:How agent memory evolved — 四代记忆系统的演进
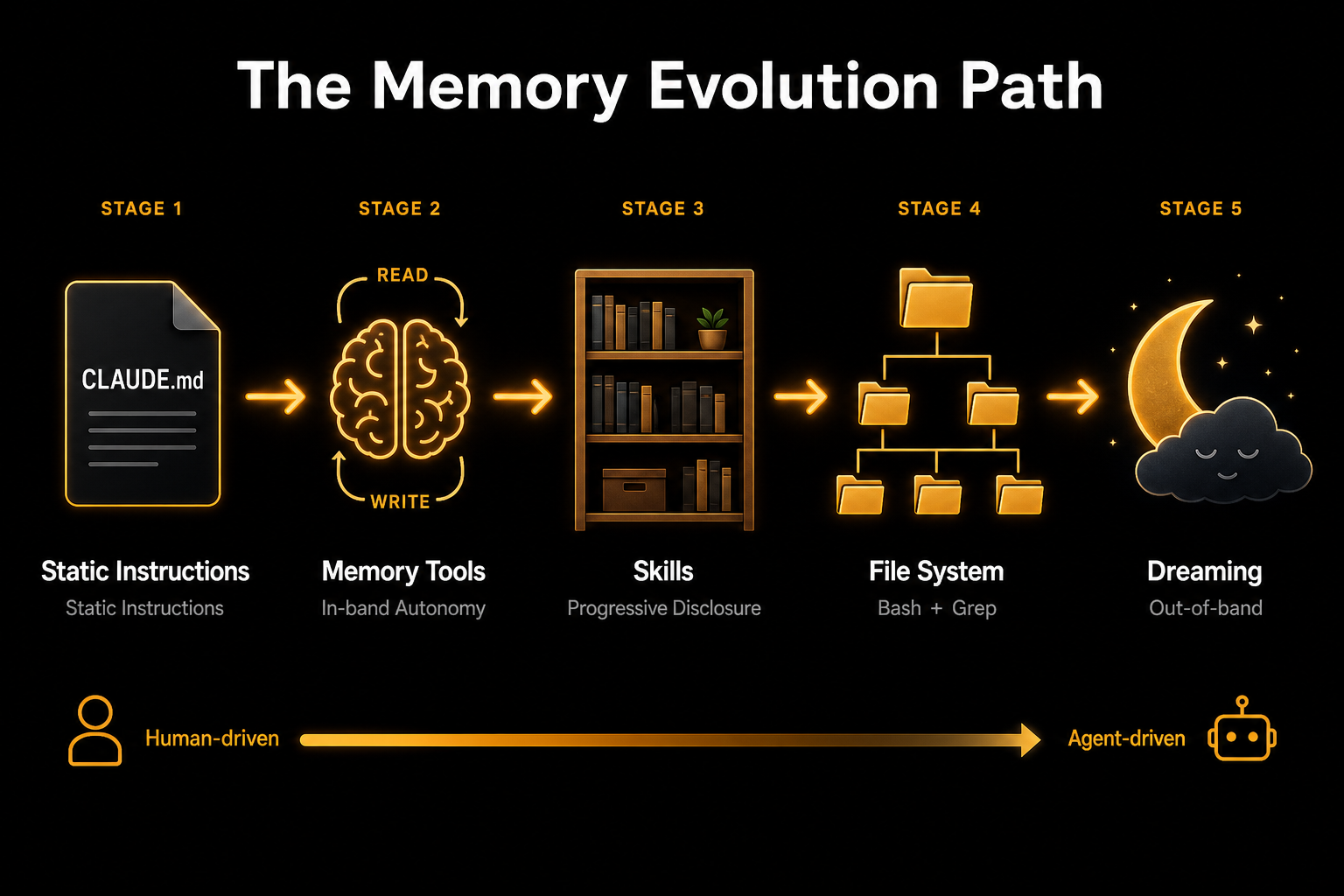
记忆进化路径:从人驱动到 Agent 自主驱动
第一代:CLAUDE.md 文件
一个 Markdown 文件,注入到模型上下文的开头,告诉 Agent:你的代码库在哪、你喜欢什么风格、你的组织有什么规范。
"What we learned was that it was unreasonably effective — this markdown file that just gives the agent a couple of instructions was so good at steering it."
效果好到不可思议。但瓶颈也很明显:文件会无限膨胀,Context Bloat 不可避免。
第二代:Memory Tools(Agent 自主读写记忆)
让 Agent 自己决定何时读取、何时写入、何时更新记忆。这是"带内"(in-band)操作——发生在会话进行中。自主性(autonomy)证明非常有效,但 Agent 在执行任务的同时还要分心管理记忆——资源竞争。
第三代:Skills(渐进式披露)
解决 Context Bloat 的精妙方案。Skill 文件只在顶部放几句简介(front matter),Agent 只需扫描标题判断是否相关,需要时再加载完整内容。Lamis 用了一个绝妙的比喻:
"It's as if I had a bookshelf in my room. Every time someone talks to me, I can scan my list of books and see if any of the titles might be relevant, and kind of pick that off the shelf and read it when I need to."
就像你房间里的书架——不需要背下每本书的内容,只需要扫一眼书脊标题,需要时再拿下来翻。局限是仍然需要人来定义"什么东西需要变成 Skill"。
第四代:文件系统即记忆(State of the Art)
当前最佳实践:把记忆系统建模为普通文件系统。
- 用 Markdown 文件存储记忆
- 让 Agent 用 Bash、Grep 等标准工具搜索——不再设计专门的记忆 API
- 通过索引实现渐进式披露
- Agent 拥有自主写入权
"Agents are actually just very good at using normal file system tools like Bash and Grep. So just let them search over the file system rather than being opinionated about the specific tools."
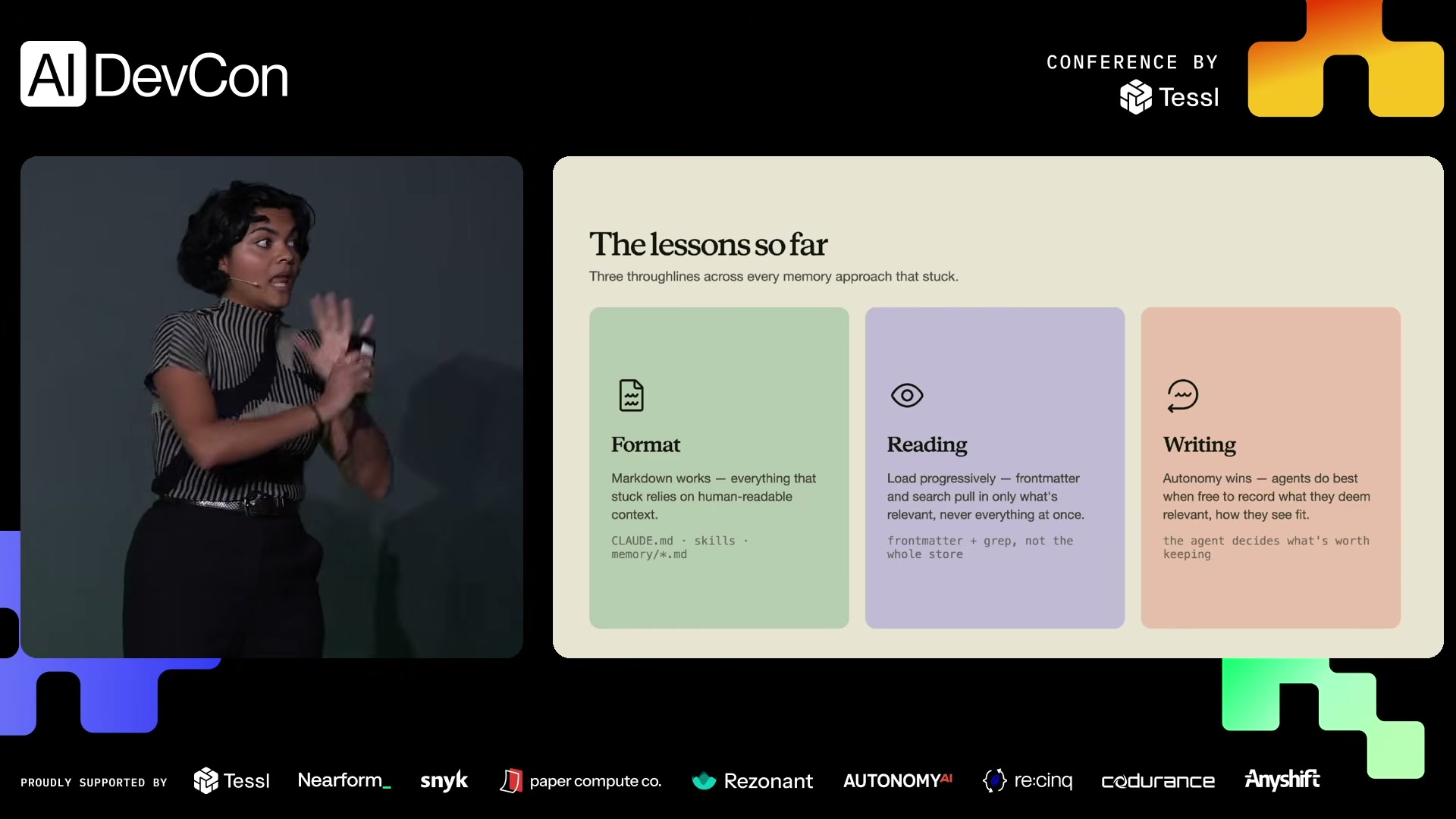
演讲幻灯片:The lessons so far — Markdown 格式、渐进式读取、Agent 自主写入
三、从理论到生产:四个工程护栏
理论上,前面的四代方案已经能让 Agent "学习"了。但规模化到生产环境时,问题扑面而来:多个 Agent 同时写同一个记忆文件怎么办?一个 Agent 错误修改了全组织共享的上下文怎么办?记忆过时了怎么办?甚至被恶意注入了怎么办?
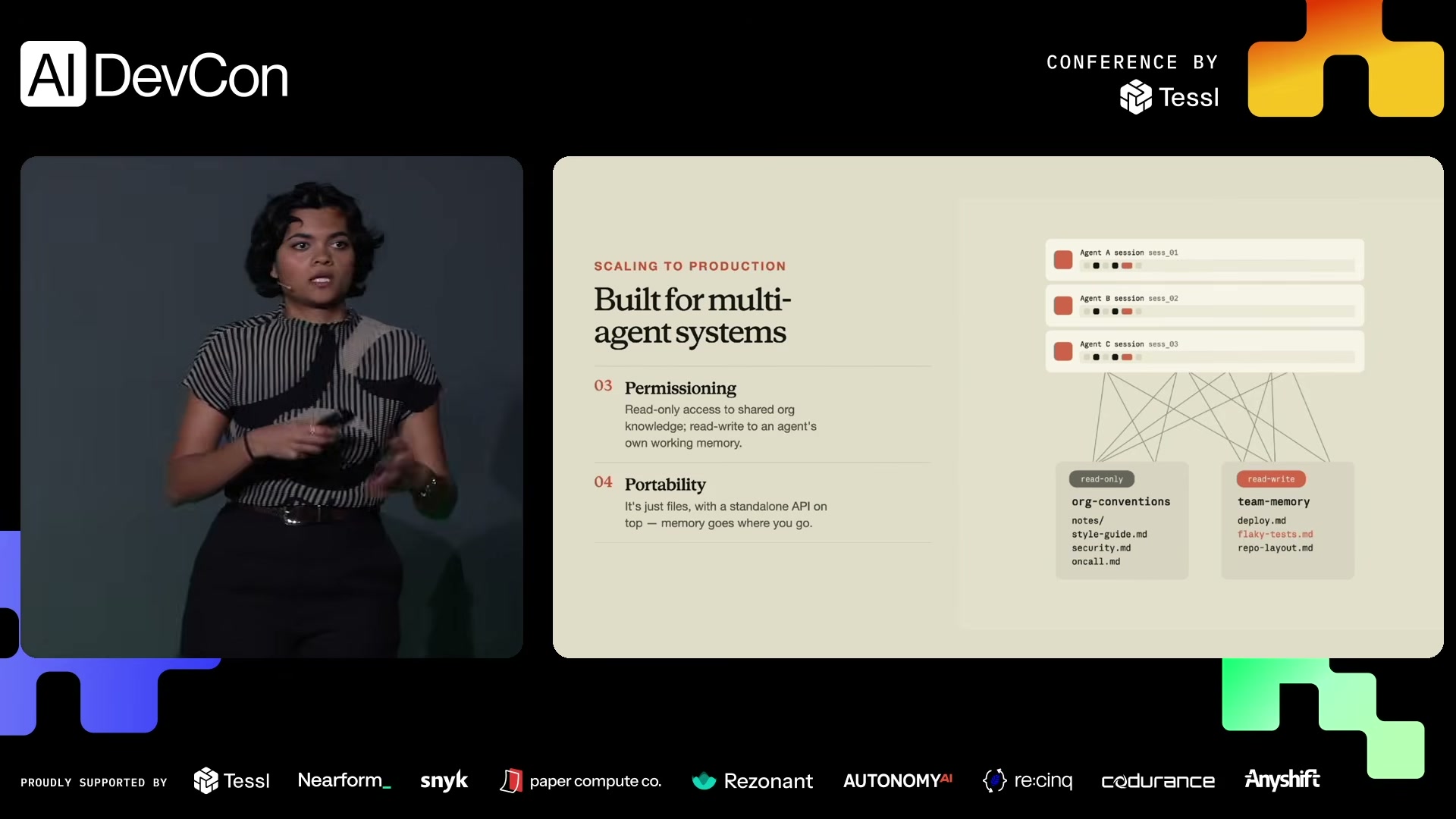
演讲幻灯片:Built for multi-agent systems — 权限分层与可移植性
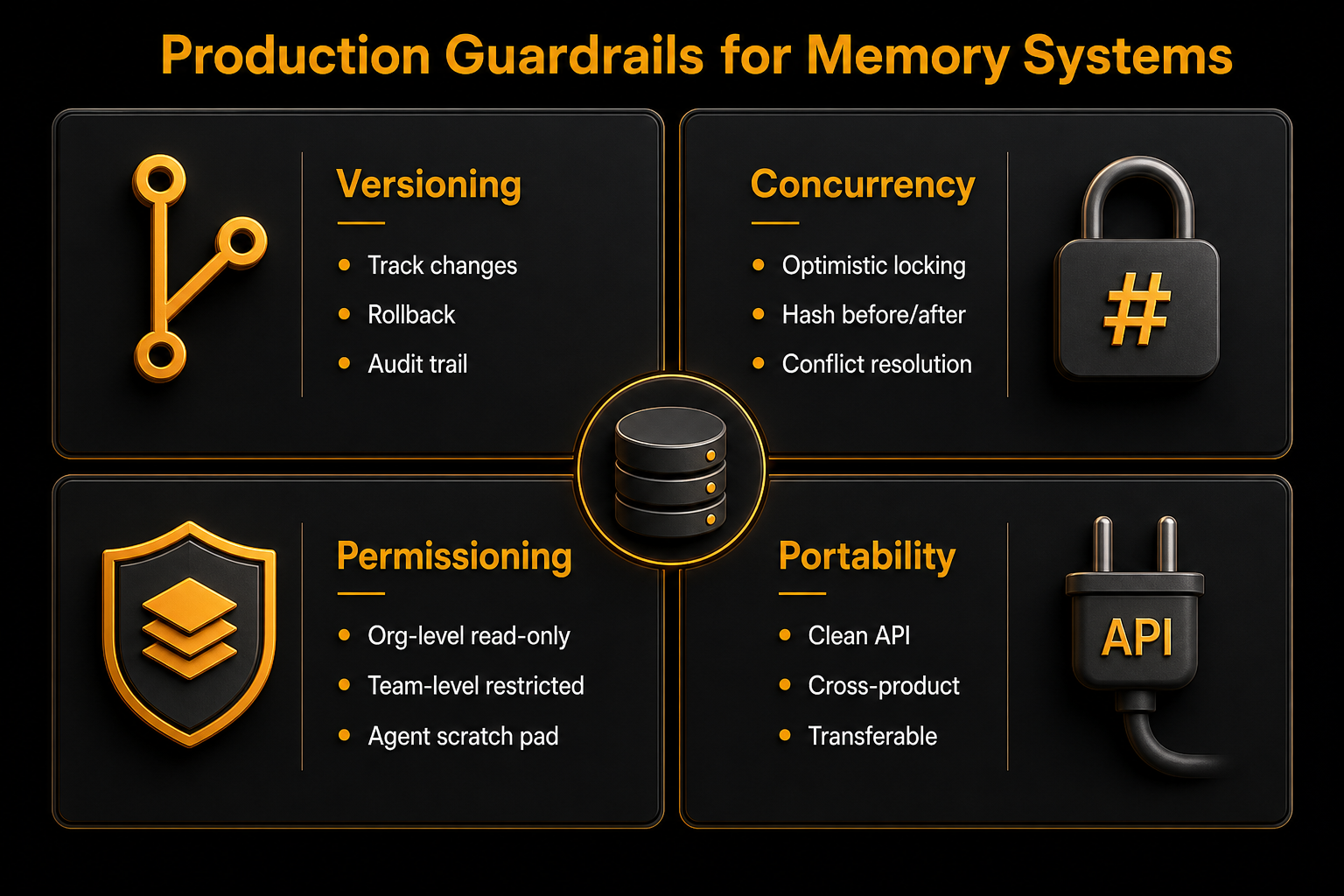
四个工程护栏:版本控制、并发控制、权限分层、可移植性
1. Versioning(版本控制)
每次记忆更新都要记录:版本号、触发更新的上下文(哪个 session / transcript)、操作者(哪个 Agent、哪个人类),以及回滚能力。
2. Concurrency(并发控制)
采用哈希锁机制——本质上就是乐观锁:
"When an agent decides to write an update to memory, it takes a hash, drafts its edit, and then before writing, takes another hash. If those two do not match, the agent cannot write it."
Agent 写之前先拍快照(取 hash),写完之前再拍一次。如果两次 hash 不匹配——说明期间有别人改过——就放弃、重新拉取、重新起草、再次尝试。
3. Permissioning(权限分层)
| 层级 | 举例 | 权限 |
|---|---|---|
| 组织级 | 公司编码规范、核心原则 | 只读 |
| 团队/项目级 | 特定代码库的架构决策 | 受限写入 |
| Agent 个人级 | 工作笔记、草稿区 | 完全读写 |
"You wouldn't want one agent to just decide that it should update the organization-wide context. Probably you'd want that as read-only. However, for its own scratch pad, you'd want it to have write access."
4. Portability(可移植性)
精心维护的记忆系统价值巨大——它应该能跨产品、跨系统使用。设计一个干净的 API,让记忆可移植。
四、带内记忆的天花板
即便做好了上述工程化,带内记忆(in-band memory)仍有两个根本局限。
局限一:资源分裂。Agent 同时要完成任务、又要维护记忆,这是一个两难的优化问题:
"How much capacity should an agent put into helping future versions of itself versus doing the task that you actually asked it to do?"
局限二:视野盲区。单个 Agent 只能看到自己当前的会话,看不到跨会话的模式。
"When you get frustrated that your agent keeps making the same mistake over sessions, it just doesn't understand how frustrating that is because it has a new context window in each of those."
你的 Agent 反复犯同一个错误——但它完全不知道,因为每次都是全新的上下文窗口。多 Agent 协作时更严重:Agent A 踩的坑,Agent B 完全不知情。
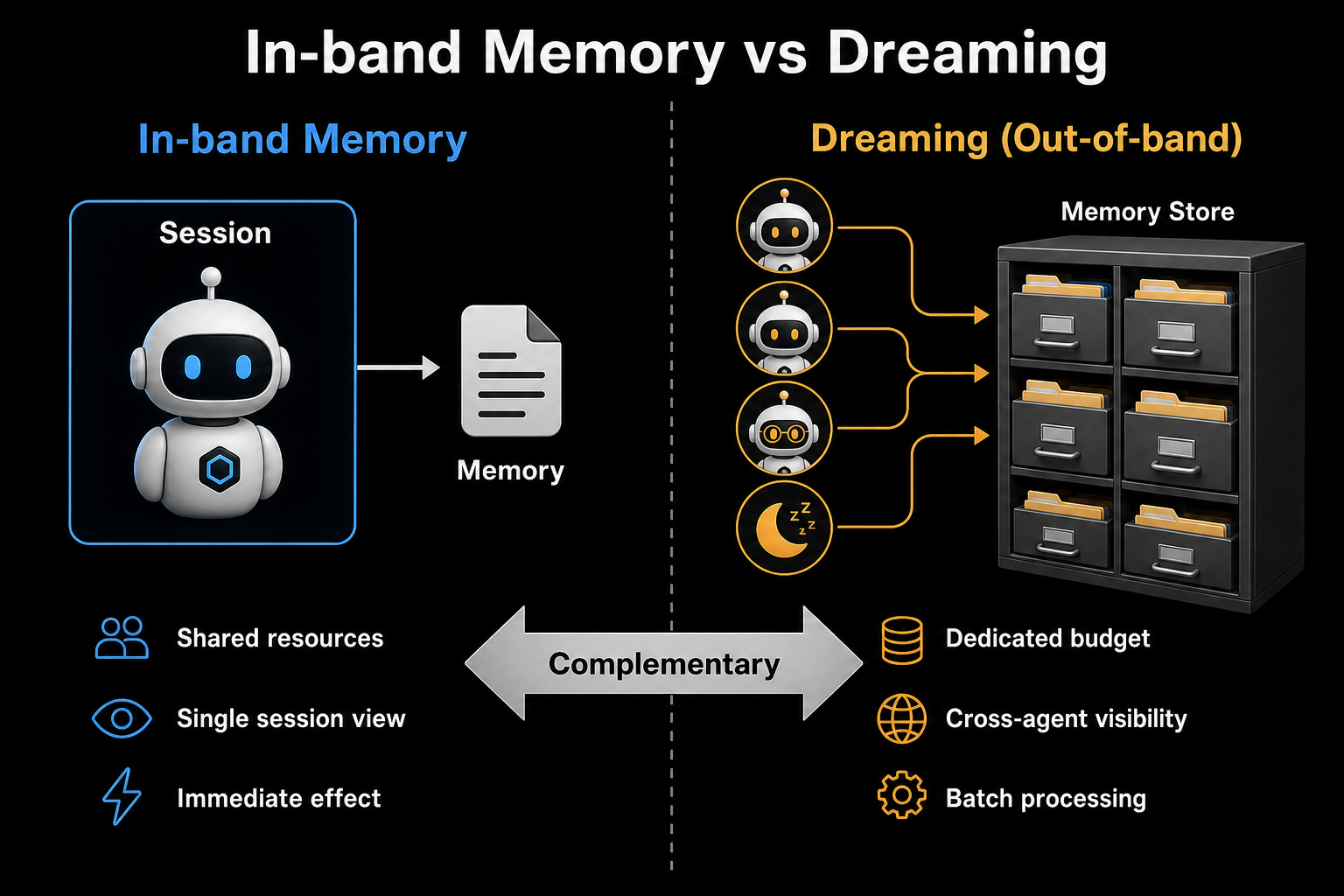
带内记忆 vs Dreaming:互补而非替代
五、Dreaming:让 Agent 在"睡眠"中学习
为了突破带内记忆的天花板,Anthropic 引入了Dreaming——一个在会话之外异步运行的"二阶"记忆整理流程。
学校类比
Lamis 的类比:把 Agent 集群想象成一所学校。学生(Agent)每天提交大量作业(session transcripts),老师(Dreaming 进程)负责批改和总结,校长(Orchestrator)纵观全局发现模式。
- 地理考试:全班某道题都答错了——检查课程大纲(memory store),发现这个主题根本没教——把它加进去
- 数学考试:所有学生都把弧度写成了角度——不是知识缺失,而是"计算器配置"问题——类比 Agent 的工具配置出错
- 全校层面:所有人都在用太多 em dash——加一条组织级写作规范
架构解剖

演讲幻灯片:How dreaming works — Transcripts → Dreaming → Updated memory state
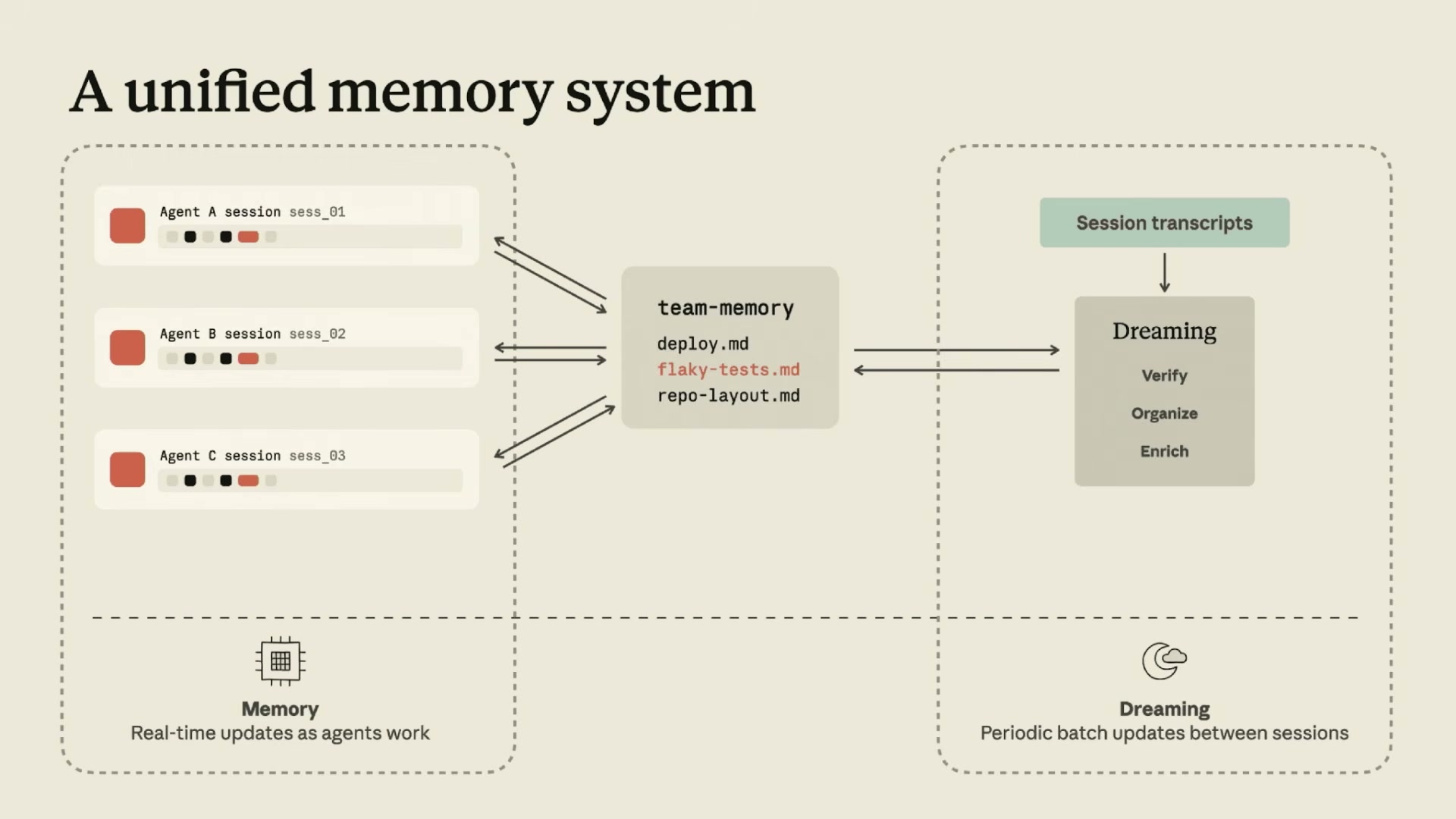
演讲幻灯片:A unified memory system — 带内 Memory(实时)+ Dreaming(批处理)双轮驱动
关键设计决策:
- 不改模型权重:只更新外部记忆层。"The system improves even if the model stays the same."
- 异步批处理:有独立的计算资源预算,不和任务争抢 token
- 可定向引导:你可以告诉 Dreaming Agent "在我的场景中,哪类信息重要、哪类不重要"
- 审计透明:每条修改建议都附带 transcript 证据 + 问题普遍程度统计
- 人类把关:最终由人决定接受还是拒绝每条修改
带内 + 带外,双轮驱动
| 维度 | 带内记忆 (In-band) | Dreaming (Out-of-band) |
|---|---|---|
| 运行时机 | 会话中 | 会话之间 |
| 资源 | 与任务共享 token | 独立预算 |
| 视野 | 单个会话 | 跨所有会话 + 跨 Agent |
| 生效速度 | 下一次运行立即生效 | 下一轮批处理后生效 |
| 适合场景 | 即时学习(这次错了下次改) | 模式识别(跨 Agent 共性问题) |
"It sounds really expensive — why would I want to chuck extra resources at this? But if we go back to the improvements, you can see costs go down because agents are able to one-shot things more effectively."
看似多花了一笔"梦境"开销,但因为 Agent 变聪明了,执行任务时的 token 消耗和重试次数反而减少——总成本下降。
六、实际部署效果
| 客户/场景 | 指标 | 提升 |
|---|---|---|
| Harvey(法律 AI) | 任务完成率 | 约 6 倍 |
| Anthropic 内部 | 任务成功率 | +10 个百分点 |
| Anthropic 内部 | .docx 文件质量 | +8.4% |
| Anthropic 内部 | .pptx 文件质量 | +10.1% |
| Wisedocs | 审查速度 | 快 50% |
Harvey 的案例尤其生动:他们的法律文书 Agent 之前在不同 session 间反复忘记"文件格式的坑"和"工具特定的变通方法",导致同样的任务反复失败。Dreaming 上线后,这些经验被持久化,失败循环被打破。
七、Q&A 精选
"有推荐的记忆存储方案吗?"
Lamis 半开玩笑地说"我们不能做产品推销",然后直接指向了Claude Managed Agents 的 Memory 和 Dreaming API——版本控制、哈希并发控制等工程实践都已经内置其中。
"Dreaming 怎么处理企业级权限?"
"When you set up a dreaming procedure, you decide exactly which session transcripts to attach. You could build a process which mirrors whatever permissioning you have on the agents."
Dreaming 不是盲目地吃掉所有 transcript——你可以精确配置它读取哪些 session,与 Agent 的权限体系完全对齐。
"我们是不是在从零开始重新发明数据库?"
全场最佳提问。Lamis 的回答很坦诚:
"To some extent we sort of are merging back into those practices, but that's because we have enough signal now to know that those things should just be done in a very deterministic way. There's no need to reinvent the wheel."
Anthropic 的路径是:先让 Agent 自由探索(Markdown 文件随便写),观察哪些 primitives 真正有效,然后把被验证的模式"硬编码"回 harness。不是重新发明轮子,而是在确认了什么该用轮子之后,才把轮子装回去。
八、关键判断
- Context Engineering 比 Model Intelligence 更值得投入——模型会自动变聪明,但上下文工程的回报是乘法关系
- 文件系统 > 专用 API——当前最佳实践是让 Agent 用 Bash/Grep 操作 Markdown 文件
- 带内记忆有天花板——资源分裂和视野盲区是结构性限制,不是工程问题
- Dreaming 不改权重——是外部记忆层的整理,不是微调或 RLHF
- 记忆系统的工程化在走向数据库化——版本控制、乐观锁、权限分层、可审计性
- 这一切只发展了一年——仍是开放的研究领域
"This journey that we've been on with context engineering — a lot of this stuff has only happened in this past year. This is very much an open area of research and development."
本文基于 Lamis Mukta 在 AI Native DevCon (June 2026) 的演讲 "Learning while you sleep: Beyond memory to dreaming" 的完整转录整理,做了结构化编排,保留了演讲者原话的引用。个别配图由 AI 生成,用于辅助理解架构概念。
视频观看:YouTube · AI Native Dev

Keep thinking, keep learning, keep dreaming.
