
本文要点(TL;DR)
- 训练 LLM 有五大支柱:架构、训练损失、数据、评估、系统。学术界偏爱架构,但工业界真正的胜负手是数据、评估与系统
- 预训练 = 自回归的下一个词预测 + 交叉熵损失;Tokenizer(BPE)把文本切成平均 3-4 个字母的 token
- 数据是预训练的命门:从 2500 亿网页的 Common Crawl,经 8 道工序清洗到约 15 万亿 token
- Scaling Laws 让你能提前预测更大模型的表现;Chinchilla 给出 20 token/参数,计入推理成本后约 150:1
- 训练 LLaMA 3 405B ≈ $7500 万、16000 张 H100 跑 70 天、约 4000 吨 CO₂
- 后训练把"续写互联网"的模型变成"听话的助手":SFT(行为克隆)+ RLHF(PPO / DPO)
- SFT 数据贵但不需多(LIMA:2000→32000 几乎无提升),它只"教格式"不教知识——幻觉可能正源于 SFT
- DPO 是斯坦福提出的 PPO 简化版,去掉强化学习、效果相当、实现简单得多,已成开源社区标配
- 对齐模型只能靠人/LLM 偏好评估:Chatbot Arena、AlpacaEval(与人类 98% 相关,但有长度偏差)
关于配图:本文配图均取自原讲座的真实幻灯片(斯坦福米色模板),少量为根据讲座内容重新整理的中文示意图(图注中标注"基于讲座内容整理")。

1. 训练 LLM 的五大支柱
开场 Yann Dubois 把话说在前头:今天讲的是 LLM 的"构建全貌",一节课压缩不了所有细节,但他想把训练一个 LLM 真正需要的每个部件都点到。所谓 LLM,就是你最近听到的那些聊天机器人背后的东西——ChatGPT、Claude、Gemini、LLaMA。
训练一个 LLM,有五个关键部件:
- 架构(Architecture):LLM 是神经网络,用什么网络结构?答案基本都是 Transformer。
- 训练损失与算法(Training loss & algorithm):到底怎么训这些模型。
- 数据(Data):拿什么来训。
- 评估(Evaluation):怎么知道自己在朝目标前进。
- 系统(Systems):怎么让这些巨大的模型在现代硬件上真正跑起来。
然后他抛出整节课最反直觉、也最重要的一句话——并且坦承这是他作为学术研究者的"自我批评":
"Most of academia focuses on architecture and training algorithms… but in reality, what matters in practice is mostly the three other topics: data, evaluation, and systems, which is what most of industry actually focuses on."
大部分学术界都在卷架构和训练算法……但实践中真正决定成败的,主要是另外三件事:数据、评估和系统——这恰恰是工业界关注的重点。
正因如此,他整节课几乎不讲架构(Transformer 网上资料已经够多,他几周前也单独讲过),而是把时间花在另外那些"信息少得多、却重要得多"的话题上。整节课分两大块:预训练(Pre-training)——经典的语言建模范式,让模型去拟合整个互联网;以及 后训练(Post-training)——把这些大模型变成 AI 助手的较新范式,也就是 ChatGPT 之后的故事。
2. 预训练 ①:语言建模与自回归
语言模型本质上就是一段 token(或词)序列的概率分布模型 p(x₁, …, x_L)。给它一句"the mouse ate the cheese",它告诉你这句话有多大可能被人类说出来或出现在网上。语法错的"the mouse ate cheese"概率应该更低(句法知识),而"the cheese ate the mouse"概率也该更低(语义知识——奶酪通常不吃老鼠)。
当下所有人在用的,是自回归语言模型(autoregressive LM):用概率链式法则,把整句话的概率拆成"第一个词的概率 × 给定第一个词时第二个词的概率 × ……"。这里没有任何近似,就是概率论的链式法则。
"There's no approximation here — this is just the chain rule of probability."
这里没有任何近似,就是概率的链式法则而已。
于是训练任务变得极其简单——预测下一个词:把词 tokenize 成 id,过一遍模型(那个"我们今天不讲"的 Transformer 黑盒),得到下一个 token 的概率分布,采样、detokenize。值得注意的是,采样和 detokenize 这两步只在推理时需要;训练时你只要拿模型预测的分布和真实出现的下一个词做对比就行。

用的损失就是交叉熵(cross-entropy):真实下一个词(如 "cat")是一个 one-hot 分布,模型输出一个预测分布,交叉熵的作用就是抬高 "cat" 的概率、压低其他所有 token 的概率。而最小化交叉熵,等价于最大化文本的对数似然——两者只差一个加负号和 log 的写法。
3. 预训练 ②:Tokenizer 与 BPE
Tokenizer 是个"大家平时不太聊、但极其重要"的部件。为什么不直接用词?因为一旦有拼写错误,这个词就没有对应的 token 了;而且像泰语这种词之间没有空格的语言,根本没法按空格切分。那为什么不干脆按字符切?因为序列会变得超长,而 Transformer 的复杂度随序列长度平方增长。
Tokenizer 就是在这两个极端之间折中:给常见的子序列分配 token,平均每个 token 大约 3-4 个字母。最常见的算法之一是 BPE(字节对编码,Byte Pair Encoding):先把语料里每个字符当成一个 token,然后反复地把"出现最频繁的相邻 token 对"合并成新 token,直到达到目标词表大小。

关于 Tokenizer,讲者回答现场提问时点出几个易被忽视的细节:
- 合并时保留小 token:万一遇到拼写错误,还能退回到按字符表示。
- 应用时贪心取最长:能切成 "token" 就绝不切成 "t"。
- Tokenizer 影响很大:数字现在的切分方式让模型"看数字"和人不一样,这正是模型数学差的原因之一;GPT-4 的一大改进就是改了代码的 tokenize 方式(比如 Python 开头的四个空格)。
4. 预训练 ③:评估与困惑度
最经典的评估指标是困惑度(perplexity):本质就是验证集损失,但取每个 token 的平均损失再做指数化,使它落在"词表大小"这个更可解释的单位里。直觉上,困惑度 ≈ 模型在生成每个词时"在多少个候选词之间犹豫"。完美模型不犹豫(perplexity=1),完全没头绪则在整个词表里犹豫。
2017 到 2023 这五六年间,标准数据集上的困惑度从约 70 降到了不足 10——模型从"每生成一个词要在 70 个词里犹豫"进步到"只在不到 10 个词里犹豫"。
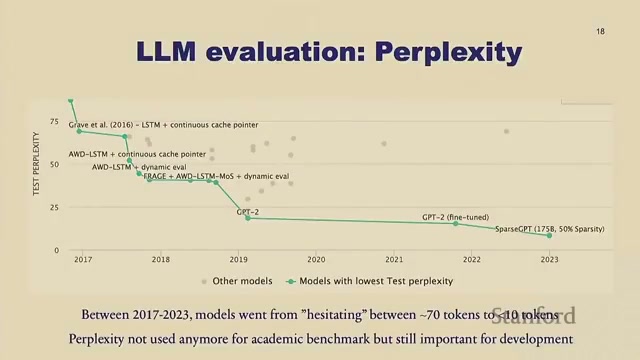
但困惑度依赖 tokenizer 和具体数据,已不再用于学术对比(不过开发自己的模型时仍很重要)。学术界现在更常把一堆经典 NLP 基准聚合起来评测,比如斯坦福的 HELM 和 Hugging Face 的 Open LLM Leaderboard。最常见的单项基准是 MMLU——覆盖大学医学、物理、天文等领域的海量选择题,通过比较模型生成各选项的似然来判分。
评估远没看上去那么简单,两个大坑:
- 评估方式不一致:同一个 MMLU,不同公司用不同评法,结果天差地别——LLaMA 65B 在 HELM 上是 63.7%,换个基准只有 48.8%。
- 训练-测试集污染(train-test contamination):对学术评测是大问题。一个巧妙的检测技巧:测试集若被训进去,模型对"按原顺序生成整个测试集"会比"打乱顺序"更有把握,而真实测试集本不该有顺序。
5. 预训练 ④:数据清洗流水线
"在整个互联网上训练"听起来轻巧,做起来是预训练里最硬核的部分。讲者直言:
"If I download a random website right now, you would be shocked at what is in there. It's definitely not your Wikipedia."
如果我现在随便下载一个网页,里面的东西会让你大吃一惊——绝对不是维基百科那样。
起点是 Common Crawl:一个每月抓取互联网新增页面的公开爬虫,目前约 2500 亿网页、约 1 PB 数据。从这堆"原始互联网"到能用的训练数据,要经过一整条流水线:

- 从 HTML 抽正文:去掉模板,难点如数学公式的抽取、论坛页眉页脚的处理。
- 过滤不良内容:NSFW、有害内容、PII(个人隐私),每家公司都有很长的黑名单。
- 去重(deduplication):重复的页眉页脚、同内容不同 URL、被转载上万次的书籍段落,都要在大规模下去重。
- 启发式过滤:用规则剔除低质文档——token 分布异常、词长异常、整页只有 3 个词或多达千万词,都是危险信号。
- 基于模型的过滤:一个很妙的技巧——拿维基百科引用链接指向的网页当"高质量"正例,训一个分类器,多保留这类内容。
- 领域分类与加权:把数据分成代码、书籍、娱乐等领域,分别上调或下调权重。比如"多训代码似乎能提升推理能力",于是上调代码占比。
- 退火阶段(高质量数据):训练末期降低学习率,在维基百科、人工收集的高质量数据上"刻意过拟合"。
- 持续预训练:用于扩展更长上下文等。
规模上,公开学术基准从早期约 1500 亿 token(the Pile)涨到现在约 15 万亿 token。闭源这边,LLaMA 2 训了 2 万亿 token,LLaMA 3 训了 15 万亿 token,GPT-4 据泄露大约 13 万亿。讲者强调数据是各家最大的秘密,既因竞争,也因版权责任——"他们绝对不会告诉你训了书,尽管确实训了,否则你可以告他们。"
6. 预训练 ⑤:Scaling Laws
这是预训练最"魔法"的一节。和 CS229 课上教的过拟合相反,LLM 世界里:
"Overfitting doesn't happen with large language models. Larger models, better performance… but for the exam, overfitting exists."
大语言模型里不存在过拟合,模型越大表现越好……不过考试的时候,过拟合还是存在的。(笑)
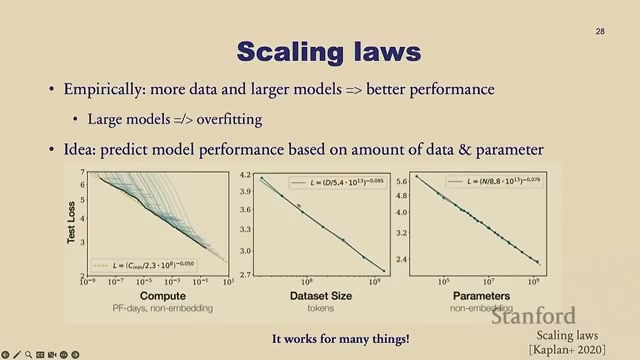
Scaling Laws(缩放定律)的核心:既然"更多数据 + 更大模型 = 更好性能"几乎总成立,那能不能提前预测到底好多少?OpenAI 那篇著名论文给出的答案是——能。把算力、数据量、参数量分别对验证损失画在 log-log 坐标上,关系是线性的。这意味着你能预测两三年后、加多少算力能达到什么水平。
"这看着平平无奇,其实很疯狂——它意味着你能预测未来。目前没有任何要 plateau(触底)的经验证据,虽然大家都觉得早晚会,但不知道是何时。"
Scaling Laws 真正的用途是指导决策。给你 1 万张 GPU 用一个月,你训什么模型?
| 旧流水线 | 新流水线 | |
|---|---|---|
| 做法 | 直接在大模型上调超参:30 天训 30 个模型各 1 天,挑最好的 | 先在不同规模的小模型上拟合 scaling law,外推出最优配置 |
| 最终模型训练时长 | 只有 1 天 | 27 天 |

同样的方法能回答"该训更大的模型,还是喂更多数据"。著名的 Chinchilla 论文给出最优配比:每 1 个参数配 20 个 token。但这是"训练最优"。如果把推理成本也算进去——小模型长期推理更省钱——则会偏向更小的模型、更多的数据,业界实际用的大模型约为 150 token/参数。
讲者借此点出 Richard Sutton 2019 年的 "苦涩的教训"(The Bitter Lesson):既然算力越多模型越好、而摩尔定律保证算力越来越多,那真正重要的就是能吃下算力的简单架构,而非那些精巧的小改动。
"Don't spend time overcomplicating. Do the simple things, do it well, scale them. That's really what OpenAI taught us."
别花时间把事情搞复杂。把简单的事做好,然后扩大规模——这正是 OpenAI 教给我们的。
7. 预训练 ⑥:一次训练要花多少钱
讲者用 LLaMA 3 405B(当时最强开源模型)做了一次"信封背面"的成本估算。它训了 15.6 万亿 token、405B 参数(约 40 token/参数,比 Chinchilla 略高,偏训练最优)。

| 项目 | 估算 | 说明 |
|---|---|---|
| FLOPs | ≈ 3.8 × 10²⁵ | 用 6 × 参数 × token 数估算;刻意压在 10²⁶ 以下,以避开拜登行政令对超大模型的特别审查 |
| 算力 | 16000 张 H100 / 约 70 天 | ≈ 2600 万 GPU 小时(官方说用了 3000 万,可能遇到些麻烦) |
| 租用成本 | ≈ $5200 万 | 按 H100 每小时约 $2 的下限估算 |
| 人力 | ≈ $2500 万 | 约 50 人 × 每年 50 万美元 |
| 合计 | ≈ $7500 万 | 讲者自评"可能差个一千万,但量级对" |
| 碳排放 | ≈ 4000 吨 CO₂ | 相当于 2000 张 JFK↔伦敦往返机票,目前还不算大问题 |
讲者给出一个直觉标尺:每一代新模型,FLOPs 大约 ×10——前提是他们能买到足够的 GPU、供得上足够的电。
8. 后训练 ①:对齐与 SFT
为什么需要后训练?因为纯语言模型并不是你想要的助手。你问 GPT-3"给六岁小孩解释登月",它可能续写出"给六岁小孩解释万有引力"——因为它在网上学到的是"一个问题后面常跟着另一个相似问题",而不是"问题后面跟着答案"。

对齐(alignment)就是让 LLM 听从用户指令、并遵守设计者的规范(比如拒绝输出有毒内容)。核心思路很务实:你想要的"问题-答案"数据很贵、网上也难找;而预训练数据虽然不是你想要的,但量极大。于是——
拿一个在整个互联网上预训练好的模型,只用很少的数据做微调,它就能学会以助手的方式说话。
SFT(监督微调,Supervised Fine-Tuning)就是在人类撰写的"理想答案"上继续做语言建模。但人工写答案又慢又贵,于是有了 Alpaca(讲者本人一年前的工作):用 175 个人类种子问答,让当时最好的模型 text-davinci-003 扩写出 5.2 万条问答,再用它微调 LLaMA 7B。这开启了如今火热的"合成数据"方向。
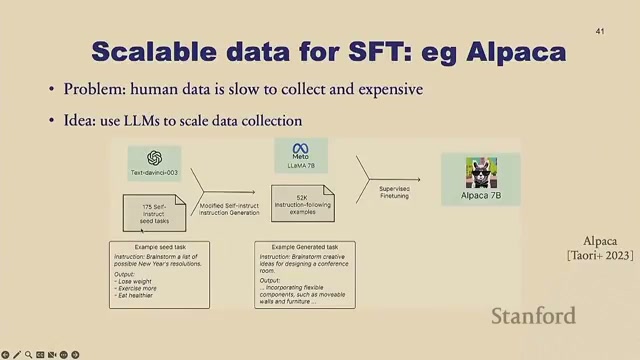
SFT 一个反直觉的发现来自 LIMA 论文:把 SFT 数据从 2000 条加到 32000 条,几乎没有提升——这里 scaling law 不灵了。讲者给出精彩的解释:
"The knowledge is already in the pre-trained LLM. With SFT you're not teaching anything new — you're just telling the model to optimize for one type of user it has already seen."
知识早就在预训练模型里了。SFT 没教任何新东西,只是告诉模型:在你见过的那么多"用户"里,多模仿这一类(会好好回答问题的那种)。
这也引出一个深刻洞见——幻觉(hallucination)可能正源于 SFT:如果人类给的答案里引用了一本模型在预训练时从没见过的书,从模型的视角看,你是在教它"编造一个听起来合理、但我根本不知道真假的引用"。
9. 后训练 ②:RLHF、PPO 与 DPO
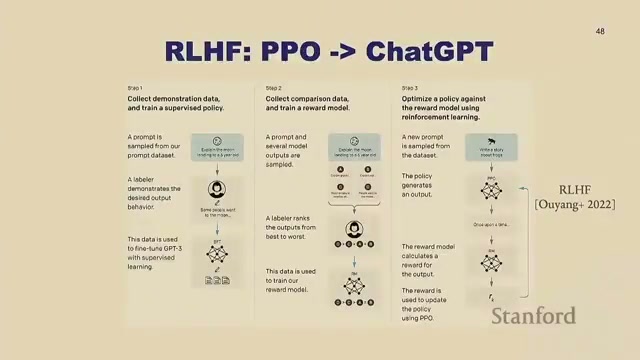
SFT 的本质是行为克隆(behavioral cloning),有几个硬伤:你被人类的生成能力所束缚(我能分辨好书,但写不出那本好书);可能诱发幻觉;逐条人工写答案还很贵。RLHF(基于人类反馈的强化学习)换了个思路:不去克隆人类,而是最大化人类偏好——对每条指令生成两个答案,让标注者选哪个更好,再让模型多生成"被选中"的那种。
怎么把"偏好"变成训练信号?两条路线:
路线一:PPO + 奖励模型
直接用"比基线好就 +1、否则 -1"的二元奖励太稀疏。更好的办法是训一个奖励模型(reward model):一个大分类器,吃进输入和某个输出、吐出一个分数,用 Bradley-Terry 模型(softmax 的 logits)来拟合人类的红/绿偏好。logits 是连续的,于是你知道"人类有多偏好"这个答案,而不只是"偏不偏好"。然后用 PPO 这个经典强化学习算法去最大化奖励,并加一个正则项防止"过度优化"奖励模型。
"Reinforcement learning is super nice theoretically, but in practice anyone who ever worked with it knows it's such a mess."
强化学习理论上很美,但凡是真上手过的人都知道,实践中它是一团乱麻。
路线二:DPO(斯坦福一年前提出)

DPO(Direct Preference Optimization)是 PPO 的极简化版:不搞强化学习,直接最大化你喜欢的答案的概率、最小化你不喜欢的答案的概率。在一定假设下,DPO 的全局最优和 PPO 的全局最优是等价的——所以这在数学上是"对的"。对比一下两条路线的复杂度:
| PPO | DPO | |
|---|---|---|
| 步骤 | 收集偏好 → 训奖励模型 → 强化学习 | 收集偏好 → 直接极大似然 |
| 实现复杂度 | 高(rollout、clipping、各种 outer loop) | 低(就是极大似然) |
| 效果 | 基本相当(PPO ≈ DPO) | |
讲者也澄清一个常见疑问——既然 DPO 这么简单,OpenAI 当初为何从复杂的 PPO 起步?因为做 ChatGPT 的正是写 PPO 的那批强化学习专家(包括 PPO 主要作者 John Schulman),对他们而言 PPO 才是最自然的选择。如今 DPO 已成开源社区(乃至工业界)的标配。
RLHF 的数据同样可以"用 LLM 替代人类"。一个惊人的事实是:
"Humans agree with themselves only around 66% of the time on a binary task."
在二选一的偏好标注上,人类和人类自己也只有约 66% 的一致率。
讲者团队五位作者讨论了三小时标注规范,准确率也才 67-68%。而 LLM 标注更便宜、与"人类多数意见"的一致率反而更高(方差小),如今约比人类便宜 50 倍。
10. 后训练 ③:如何评估对齐模型
对齐后的模型没法用验证损失或困惑度评估(PPO 训出的是"策略"而非分布,困惑度失去意义),而且答案开放、没有唯一正解。于是评估方式回到人类/LLM 偏好:
- Chatbot Arena:让网友盲测两个聊天机器人、投票更好的那个,几十万次投票后得到排名。最受信任,但用户偏技术圈、问题偏技术向。
- AlpacaEval(讲者本人的工作):用 GPT-4 当裁判自动判分,与 Chatbot Arena 相关性高达 98%,跑一次不到 3 分钟、不到 $10。

但 LLM 裁判有个顽固的长度偏差(length bias):
"If you've ever been annoyed at ChatGPT answering you super long — this is because of RLHF."
如果你曾被 ChatGPT 动不动回你超长的答案搞烦——这正是 RLHF 造成的。
人和模型都偏爱更长的回答,但人类有底线(五页废话我会嫌烦),模型一旦带上这个偏差就会一路放大。证据很直接:同一个 GPT-4 自己跟自己比本该是 50% 胜率,但提示它"啰嗦点"胜率升到 64.4%,提示它"简洁点"则跌到 20%。AlpacaEval 后来用因果推断做长度控制,才把这个偏差大幅压下去。
11. 系统:让 GPU 不闲着
既然算力是最大瓶颈,"为什么不多买 GPU"并不成立——最好的 GPU 又贵又稀缺,多卡之间通信还要花时间。所以关键是怎么优化你的流水线。几个基础事实:GPU 为吞吐优化(CPU 为延迟优化),擅长矩阵乘法(能用矩阵乘就快 10 倍);近年算力的增长快于内存和通信,所以不优化的话,GPU 大部分时间其实在空等数据。
衡量指标是 MFU(模型 FLOP 利用率):实测吞吐 / 理论峰值。能到 50% 就很满意了——讲者说他看 LLaMA 大约是 45%,意味着即便这些大公司,数据也喂不够快。讲座重点讲了两个"让 GPU 不闲着"的技巧:

- 低精度(low precision):把浮点数从 32 位降到 16 位,更少的比特 = 更快的通信、更低的显存。深度学习对小数精度不敏感(SGD 噪声本来就大,把权重更新 0.01 还是 0.015 无所谓)。标准做法是混合精度:权重存 32 位,计算前转 16 位、算完再以 32 位更新。
- 算子融合(operator fusion):每行 PyTorch 都会把数据在 GPU 全局显存和计算单元之间来回搬一次,极其浪费。融合的思路是一次搬运、做完所有计算、再搬回来。最实用的一招——给模型加一行
torch.compile,它会把代码重写成 C++/CUDA、只通信一次,通常提速约 2 倍。
讲者因时间关系跳过了 tiling、并行化和混合专家(MoE)——并强调它们同样重要。
12. 展望与延伸学习

讲者坦诚一节课远讲不完,没碰的还有很多:架构(MoE、SSM)、解码与推理、多模态、UI 与工具(ChatGPT 的最大创新或许就是一个好用的 UI)、滥用、上下文长度、数据墙(互联网数据可能不够训未来的模型)、以及数据采集的合法性。
如果想深入,他推荐三门斯坦福课程:
| 课程 | 内容 |
|---|---|
| CS224N | 对 LLM 着墨最少,但给足 NLP 的背景与历史脉络 |
| CS324 | Large Language Models,对本讲所有内容的更深入阅读与讲授 |
| CS336 | Language Models from Scratch,从零亲手造一个 LLM——内容硬核、工作量极大,由讲者的两位导师开设 |
纵观全场,这节课最值得带走的,是那条贯穿始终的主线:真正决定 LLM 成败的,往往不是最吸引眼球的架构创新,而是数据、评估与系统这些"脏活累活"。把简单的事做好,然后扩大规模。
本文据斯坦福 CS229 客座讲座 《Introduction to Building LLMs》(讲者 Yann Dubois,2024-08-13)英文原声整理。配图取自原讲座幻灯片,版权归讲者及斯坦福所有。
中文精读整理:AI 辅助